4 Common Product Discovery Mistakes (and how to avoid them)
Hey I’m Ant and welcome to my newsletter where you will find actionable posts on all things product, business and leadership.
You might have missed these recent posts:
- OKRS ≠ Strategy
- Building Effecive Product Roadmaps
- Asking Better User Interview Questions
My day job is helping companies shift to a Product Operating Model.
My evening job is helping product people master their craft with Product Pathways.
If video is more your thing, check my Youtube channel out!
A few weeks ago I had the privilege of sitting down with Priya Seevaratnam, Head of Growth over at Floik to chat about Product Discovery.
You can watch the full conversation here.
One of the questions Priya asked me was on the common challenges that I see with my clients around Product Discovery.
This got me thinking about the most common mistakes that I see teams make with product discovery. I thought I’d package that up in this week's post and, of course, include actionable steps you can take to avoid them.
Let’s get into it!
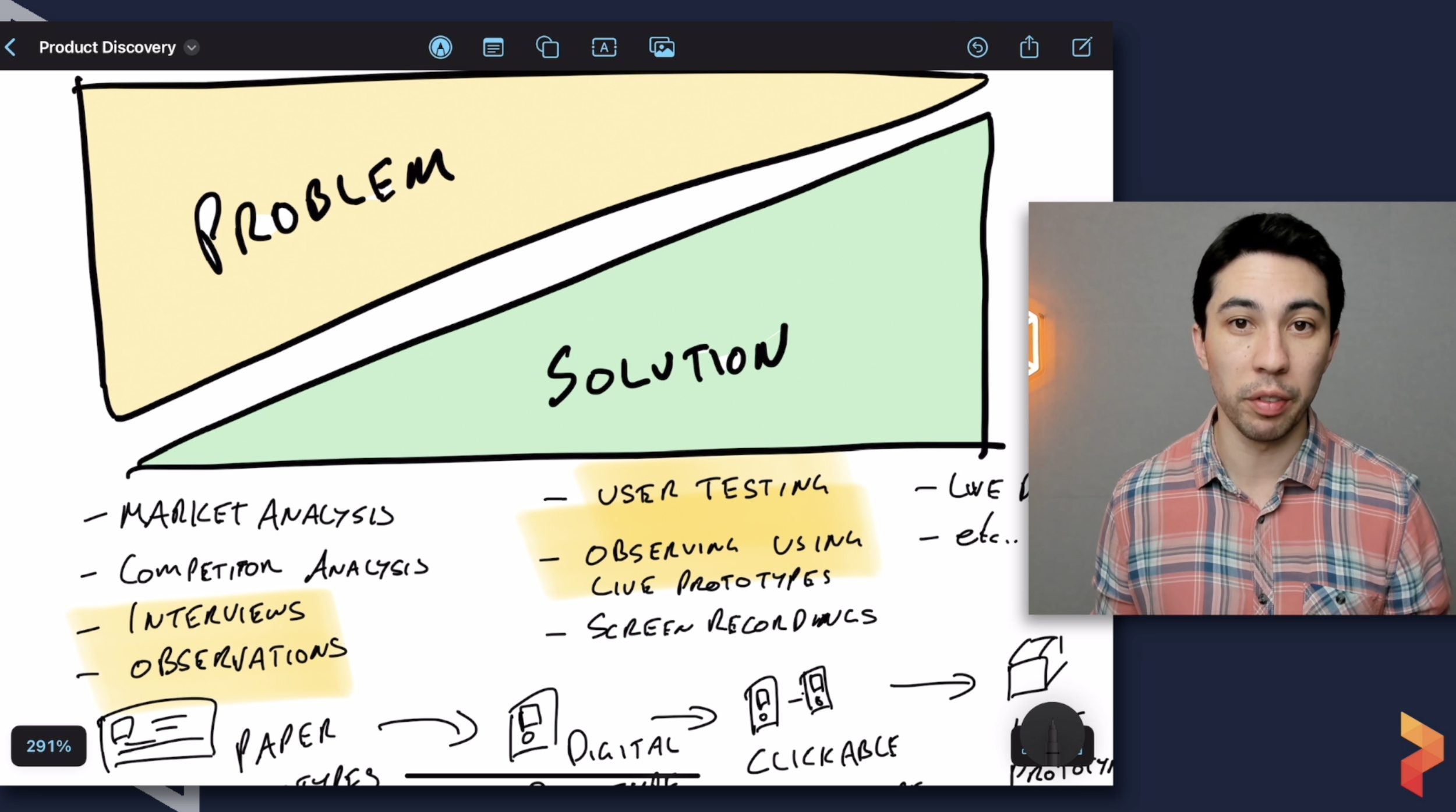
1) Spending Too Long in Discovery
Yep, that’s right, a common mistake I see is spending too much time on discovery.
But wait. You’re probably thinking; “what? We don't spend ENOUGH time on discovery!”
Let me explain as this might not be you - but even if it’s not, I want to touch on an important Discovery practice that I think all teams should do.
I often see companies doing these big long (3+ months) discovery cycles.
Common causes are:
they’re not breaking down the outcomes/problem space first
they’re not doing continuous discovery
or a combination of the two.
Discovery should be lightweight and a continuous activity.
This helps us avoid hitting the point of diminishing returns.
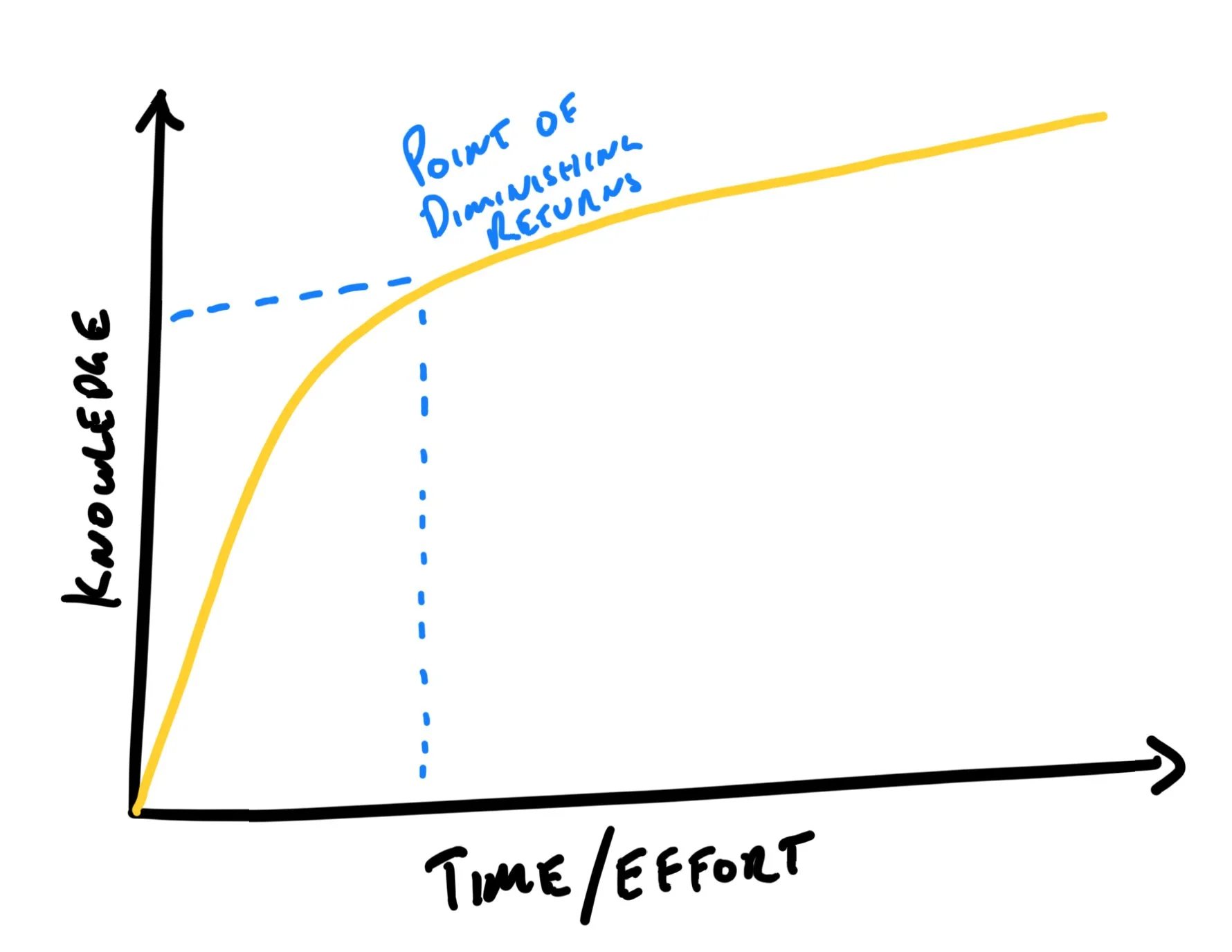
We can spend forever trying to learn everything. However there’s a point where we’ve learned enough to make an informed decision and move on.Inevitably, there will be a point in discovery where investing more time to learn more will only yield a small benefit.
At this point, the time invested in more discovery outweighs the additional benefit.
Apart from continuous discovery, another way to help avoid passing this threashold is to timebox discovery.
SOLUTION: Timebox Discovery
I learned this great tool from a mentor of mine who is a Principal Product Designer. I later found out that he got the model from Jeff Patton (pic below).
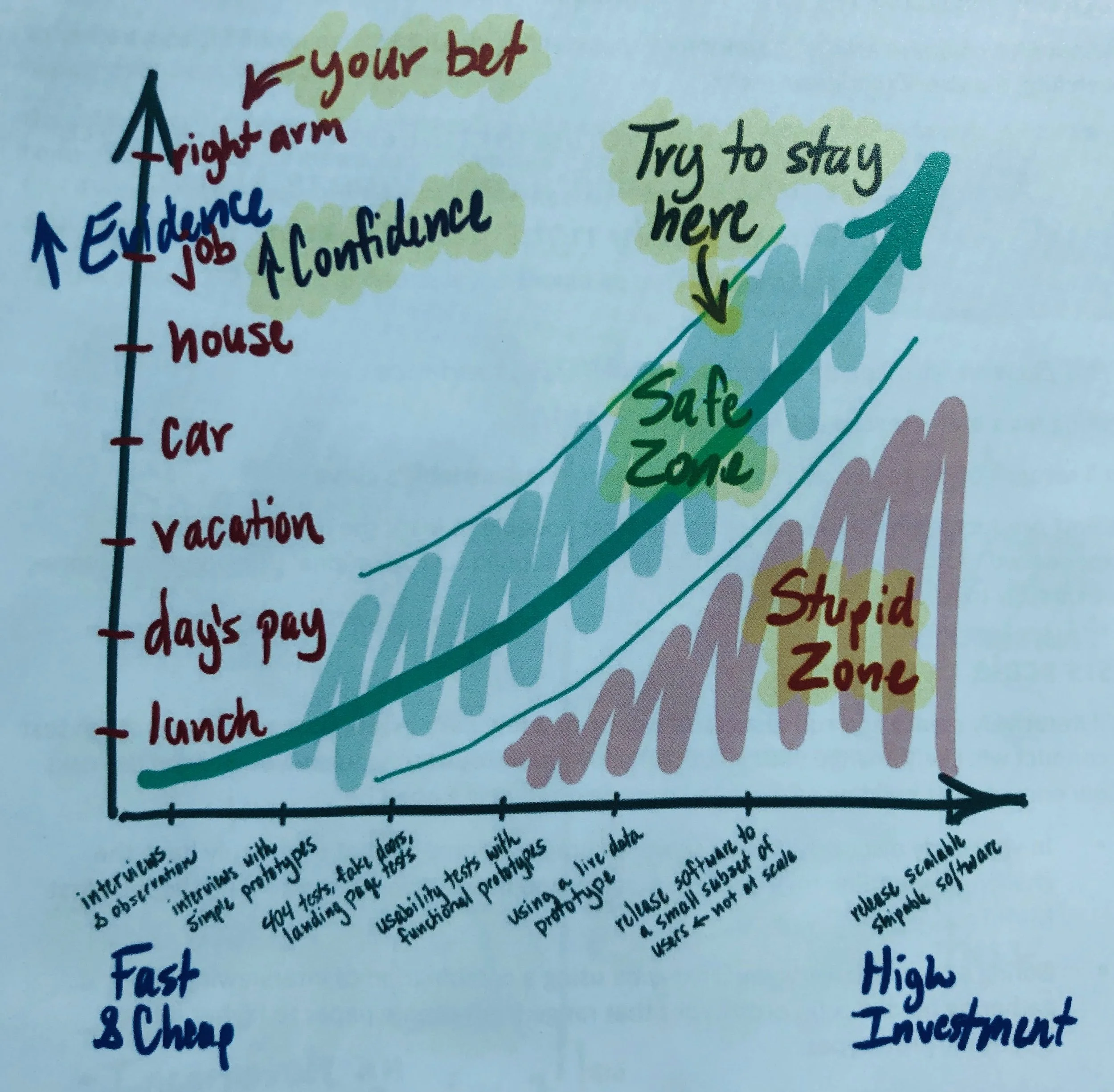
Credit Jeff Patton. Pic from his Passionate Product Leadership course workbook.The way the model works is along the y-axis is ‘confidence,’ - or you can think of it as the amount of existing evidence we have.
The x-axis then denotes high vs low investment into discovery.
The ‘sweet spot’ is then a balance between how confident you are about the idea and how much investment you put into discovery.
When confidence is low, we should invest more in discovery as the risk of being wrong is higher and when confidence is high, we may not need to invest much time, if any, into discovery as the risk is low.
When we don’t do enough discovery on something we end up in the “stupid zone,” increasing the likelihood that we end up building something that doesn’t solve a problem or isn’t the best possible solution.
And when we do too much discovery, we simply waste time.
So, there’s a safe zone that we ideally want to stay within.
I use this model all the time to help facilitate a conversation about how much time we should invest in discovery.
I do this in collaboration with those who are tasked with doing discovery, typically after we’ve framed the problem space and completed an assumptions map (more on this in a second).
Learn more about how to kick off product discovery and set an initial timebox in my Product Discovery Kickoff Workshop.

2) Not Testing Your Assumptions
Discovery should be intentional.
It’s not asking your users random questions about your product.
Nor is it about asking your users what they want - this is where the (often attributed to) Henry Ford quote gets it wrong.
Discovery is about gaining confidence to decide on what you’re ultimately going to build (if anything).
We do this through a series of activities, through which we learn more about the problem and solution space. In doing so, we reduce the risk of the solution being either not viable, feasible, or desirable.
Therefore, discovery must be focused on testing your assumptions.
More specifically, your riskiest assumptions.
Assumptions introduce risk as we don’t know for certain - that’s why they’re assumptions!
For example, for Uber, there was a big assumption that people would be willing to get into strangers’ cars.
Now, if that turned out to be false, Uber would fail.
There’s no way that Uber would have worked if that assumption wasn’t true.
So, this is the basis of discovery. We want to invest time into validating* our assumptions.
(*I use validating loosely here. As one of my best friends, who’s a biochemist, will point out, we're far from doing scientific validation in Product Discovery, and that’s ok.)
SOLUTION: Assumptions Mapping
I cannot imagine starting discovery any other way than with an assumptions map.
Assumption Mapping is a technique developed by David J. Bland.
I was first introduced to the technique through his book Testing Business Ideas.
As the name suggests, assumptions mapping is where you map your assumptions against a 2x2 matrix where you have Importance along the y-axis and whether or not you have evidence along the x-axis.
I highly encourage you to do this collaboratively, as a product trio at a minimum.
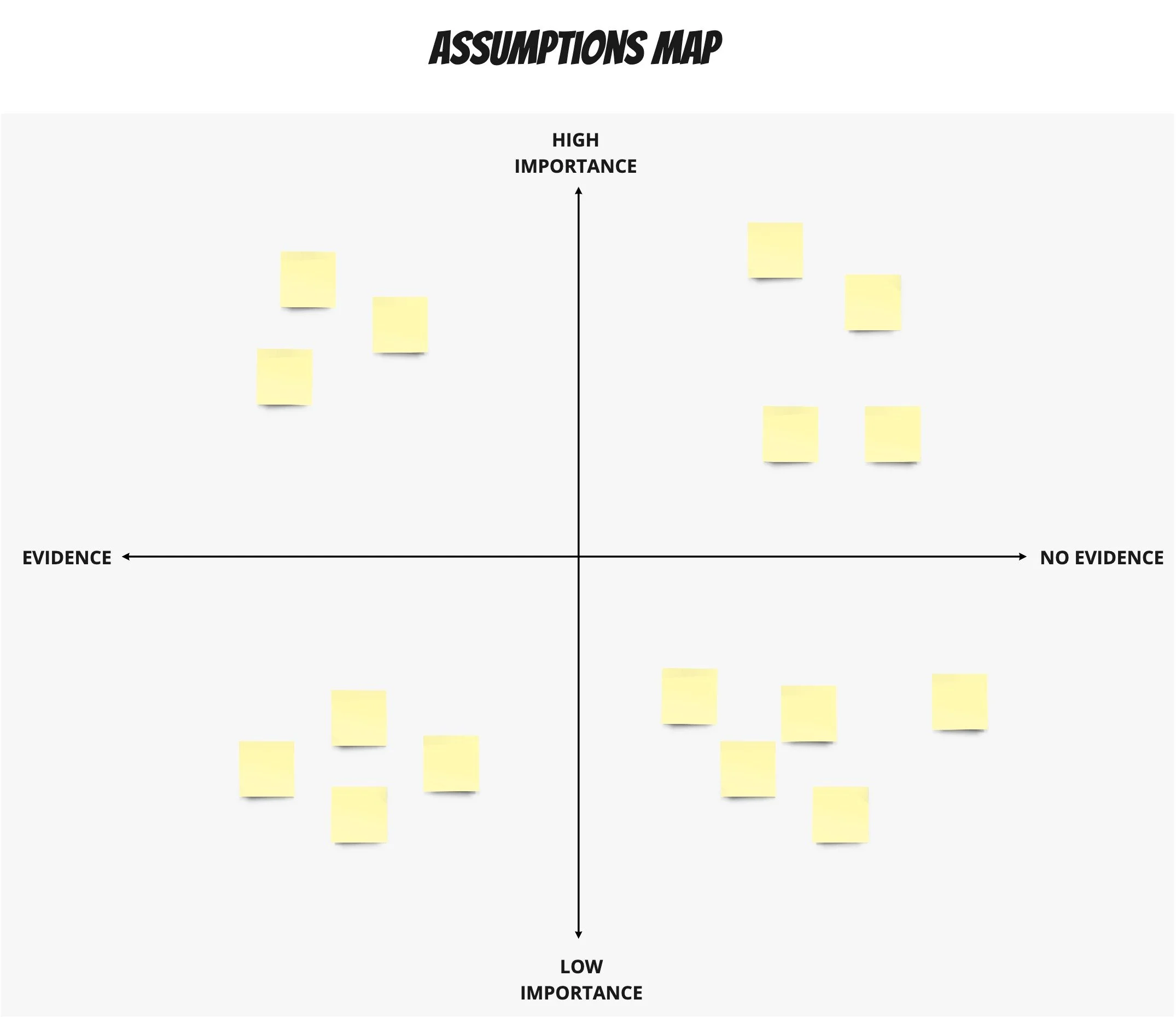
Assumptions MapOnce you’ve mapped out your assumptions, those in the top right corner would typically be your riskiest assumptions - you want to start here.
By starting with your riskiest assumptions, you ensure you’re getting the best ROI out of discovery.
You can read more about assumptions mapping here.
…and more about how I turn assumptions into hypotheses and tests here (including link to an Experiment Board template)

Experiment Board Template from ‘How to Kick off Product Discovery like a Pro’3) Only Interviewing Existing Users
I have to tell you this story!
I’ve recently been working with a Head of Product who joined a scale-up here in Australia.
He was looking at a bunch of research that the design team had recently done. Long story short, they’re working on a new product offering—without giving sensitive information away, all you need to know is that it’s an offering for a new market segment (not their current customers). The design team, through no fault of their own, had done all this great research and interviewed ~20 customers, except they only spoke to existing customers. Who are not the target market for this new product.
Unfortunately, this made their research unreliable.
It’s like asking non-parents questions about parenting. It’s better than nothing, but it’s not as good as speaking with actual parents.
Unfortuantely, this story is all too common.
I see a lot of teams only speak with their current users.
The problem is selection bias.
In WW2, returning planes from the battlefield were analyzed to make suggestions on where reinforcement should be made.
The problem was that the planes they analyzed were only those who managed to make it back ok. Meaning that the data set didn’t include any planes that crashed or suffered fatal damage.
Ironically, this meant that they were only really reinforcing parts of the planes that could actually sustain damage - not the parts that needed it most.
This phenomena is often called survivorship bias - a form of selection bias.

A popular visual representation of survivorship bias. Credit wikipediaImagine you want to improve onboarding or increase conversion.
If you only speak to your existing users, you will only hear from those who successfully made it through onboarding or converted—survivorship bias.
SOLUTION: Interview Guide
One of the ways I try to avoid this mistake is by developing an interview guide.
Despite covering a range of things:
What problem we’re trying to solve?
What’s the goal of the interview?
Interview questions and structure
Assumptions being tested (or not tested)
Who are our ideal user(s) that we wish to interview
etc…
If you’re lucky, you will have the privilege of working with a Research Ops team or an experienced User Researcher who would likely own a lot of this work and are experienced in ensuring you don’t fall into this trap.
But if you don’t, you want to make sure you have a section in the interview guide to define your ideal user to interview.
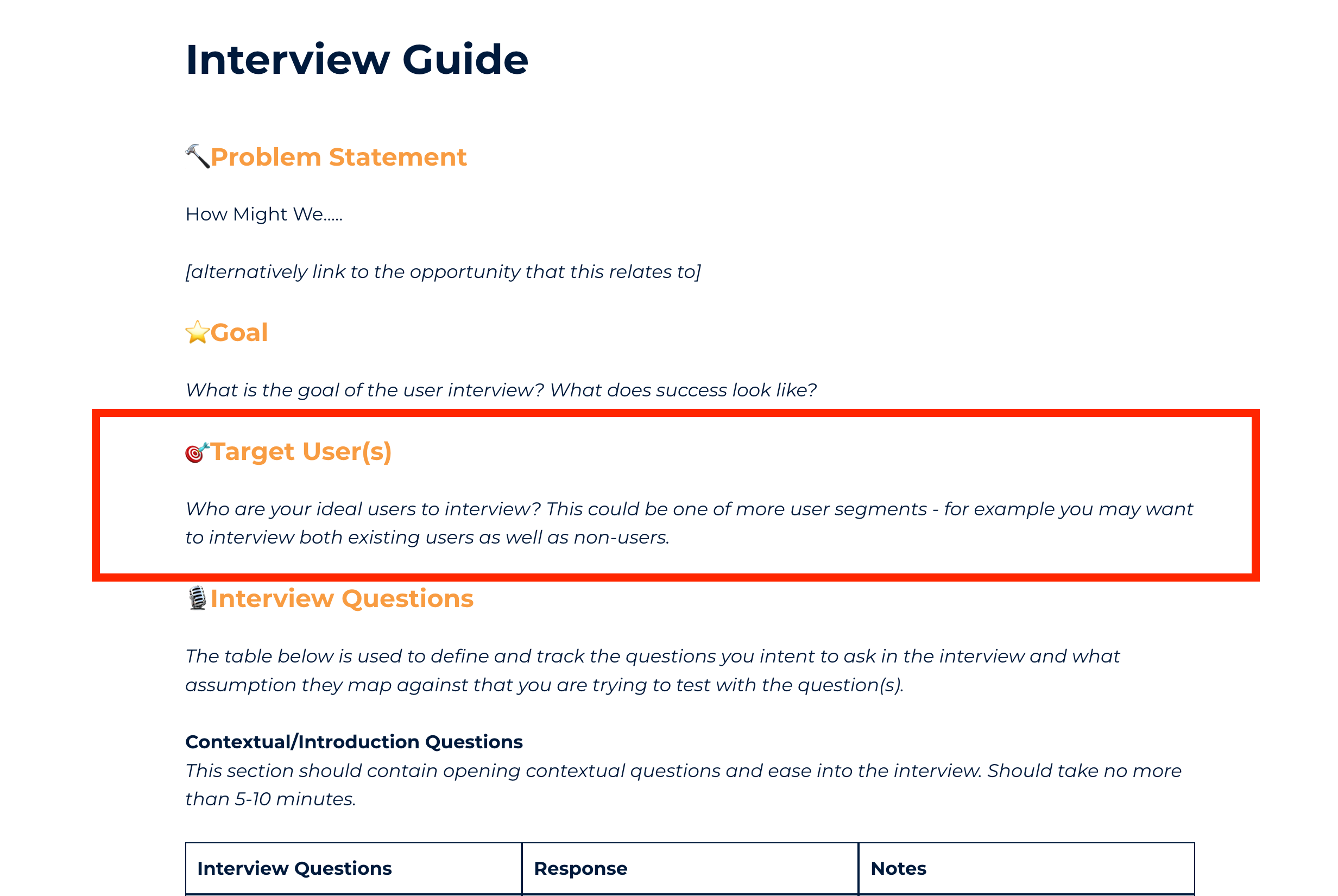
Spend time defining your target user(s) that you wish to interview. This should be based on the problem you’re trying to solve and the assumptions you want to test. Get this Interview Guide template here.Further down the template, I typically include a table to recruit and track user interviews.
Again, you may have an experienced Design Lead or User Researcher who can help or even own this.
To get really tactical for a second, I use this table to create a list of the different types of users I wish to interview and their defining characteristics—basically filling in everything except for their name as I haven’t recruited anyone yet.
I would then use that list to go out and recruit users.
If you need help recruiting non-users to interview, read these 5 B2B user recuitment strategies here.
Also check out Orbital if you’re after tooling to help you do the heavy lifting for recruiting and scheduling user interviews.
Note: I don’t have any financial relationship with orbital, I just know Raphael Weiner and I think they’re doing some good work and solving a real problem for product teams.
The best part about tracking all this in one table is that it quickly becomes obvious if you have selection bias or not.
Sometimes, it’s unintentional. For example, you may have a bunch of the same type of users cancel, which can easy to go unnoticed unless you have this level of visibility.

Table to recruit and track you users interviews. From this template.4) Not Gathering Multiple Inputs
Like selection bias, the final common mistake I see product teams make is not gathering and cross-checking with multiple data sources.
This is a good practice as it helps to avoid biases (including selection bias).
It’s easy to (unintentionally) manipulate data to support an idea or assumption. It’s hard to do that across multiple different data sets.
For example, whilst I was at ustwo, we did some discovery for a client around fuel stations and truck drivers.
The problem space was that not all fuel stations support large semi-trailer trucks. Some are too tight to maneuver in and out, others are too low and the truck would take the roof off, etc.

Many fuel stations aren't suitable for large semi-trailer trucks - like this one!When we look at the fuel station data, this is true.
A large number of fuel stations weren’t suitable for large semi-trailer trucks.
But does this validate the problem?
You could easily argue that it does - “X% of service stations are unsuitable for semi-trailer trucks, leading to Y impact.”
But if we were to dive into a few more data points and assumptions:
How many of the fuel stations are on major truck routes?
How often do truck drivers struggle to find a fuel station where their trucks would fit?
If they ran into this issue today, how do they solve it? (is this problem already sufficiently solved)
Once we pieced several more data points together and interviewed many truck drivers, we found this wasn’t a big enough problem.
I won’t bore you with the full story, but here are some of the key findings:
Semi-trailer truck drivers typically drive the same route and are familiar with the suitable fuel stations
When taking over a new route, semi-trailer truck drivers normally ride the route with the current driver before doing it alone.
It was uncommon for semi-trailer truck drivers to be on the road they weren’t familiar with, but in the unlikely event that they were, if they needed help, they would ask the ‘trucker network’ via CB Radio, which would typically give them a swift and up-to-date response.
Sidebar: using CB Radio in Australia is legal to use whilst driving, whereas we have strict mobile phone laws making CB Radio a more desirable choice over, say, Google Maps or any other mobile solution we could come up with when driving.
SOLUTION: Multiple Tests
Hopefully, the solution to this one is quite obvious.
When you’re testing assumptions, you must also test it from different angles.
A few things I always try to do:
When interviewing, ask 2-3 questions to test the one assumption.
Avoid 1:1 from assumption to question, unless the assumption is straightforward and could be tested with a ‘yes/no’ type question.
Make sure I have a mix of qualitative and quantitative data.
Avoid making a decision on a single data point. Get at least one more to confirm, ideally 2-3 more.
Wrap up
When I posted this list on LinkedIn, a few people replied to emphasize a few of the points.
The main one was #2, testing your assumptions.
As Michael Goitien said: “Number 2 is the big one, Ant Murphy. Without examining our underlying assumptions, Discovery just becomes a weak form of validation.”
I couldn’t agree more!
Konstantin Münster also reinforced that assumptions mapping as a tool, is a great solution for both #1 and #2. “Love the assumption mapping part! When building MVPs with clients, this is also one of the first things we do. It also helps avoid number 1, spinning wheels infinitely on discovery.”
This is spot on. Using both assumptions mapping to prioritize your riskiest assumptions and then working within a timebox ensures that you’re spending your time in the highest-leverage way.
If you’re looking for a place to start on this list, I recommend starting with #2 first and then #1 second - if you can do both at the same time, great!
Keen to hear which one resonated the most with you!
Or what did I miss?
Need help with scaling your product or business? I can help in 4 ways::
Level up your craft with self-paced deep dive courses, FREE events and videos on YouTube, templates, and guides on Product Pathways.
1:1 Coaching/Mentoring: I help product people and founders overcome challenges through 1-hour virtual sessions.
Consulting and Advisory: I help companies drive better results by building effective product practices.
Private Workshops and Training: I run practical workshops and training courses for product teams globally.
Top Posts









Your OKRs don’t live in a vacuum.
Yet this is exactly how I see many organizations treat their OKRs.
They jump on the bandwagon and create OKRs void of any context.
Here’s what I see all the time…